El 16 de abril de 2016 a las 18:58UTC-5 un terremoto de magnitud 7.8 Mw azotó la costa ecuatoriana. Su epicentro, en el cantón Pedernales, provincia de Manabí, ocurrió en una zona sismológicamente activa debido al fenómeno de subducción; según la USGS, siete sismos de magnitud superior a 7 Mw han ocurrido en esta zona desde el inicio del siglo XX. El de 2016 fue una catástrofe que provocó más de 600 fallecidos, miles de heridos y varias localidades manabitas afectadas, como Pedernales (con alrededor del 70 % de su infraestructura destruida), Manta y Portoviejo. También hubo afectaciones en la vecina provincia de Esmeraldas, e incluso en otras más alejadas como Guayas y Pichincha.
La imagen de portada fue adaptada a partir de una fotografía de la Agencia de Noticias ANDES, publicada bajo licencia CC BY–SA 2.0, vía Wikimedia Commons
{kind=link}
En los días siguientes varios proyectos —de origen nacional e internacional— contribuyeron con rescatistas, médicos, víveres, albergue y conocimiento técnico, entre otras cosas. Este artículo, redactado en el quinto aniversario del evento, trata sobre el proyecto que contribuyó en el aspecto cartográfico de la gestión de la emergencia: Mapping Ecuador tuvo como propósito “crear mejores mapas que apoyen las labores de socorro y reconstrucción”. La manera de lograr esto fue insertar en la plataforma OpenStreetMap (OSM) el estado pre–terremoto de las zonas afectadas. El proyecto fue organizado por LLACTALAB de la Universidad de Cuenca y el Humanitarian OpenStreetMap Team (HOT), recibiendo contribuciones de cientos de usuarios OSM de varias partes del mundo.
La primera vez que encontré los resultados de Mapping Ecuador fue en el sitio web OSMstats, que reporta información estadística sobre OpenStreetMap. La página de Ecuador presenta valores atípicos en abril de 2016 que solo pueden ser explicados por un evento de contribución masivo. En este artículo1 presento un vistazo a algunos aspectos de esas contribuciones; particularmente, trato de observar cómo este proyecto influyó a la comunidad que mapea en el país. Para esto utilicé dos fuentes: el mismo sitio OSMstats, y la API Overpass para obtener datos OSM.
Datos OSMstats
Para utilizar datos del sitio OSMstats, previamente se aplicó el método web scraping y se
generó un dataset con observaciones semanales correspondientes a Ecuador2. Considerando que en dicho sitio web existen
observaciones diarias, es claro que se debió aplicar alguna función a cada variable, para reducir
la periodicidad de las observaciones, de modo que sean semanales. El dataset generado es
ecuador_osmstats_2021_week_14.csv
y contiene las siguientes variables:
Weekes la fecha correspondiente al inicio de cada semana, de acuerdo al estandar ISO 8601; considera que las semanas comienzan los días lunes, y la semana que contiene el primero de enero es la primera del año, solamente si contiene cuatro o más días en el nuevo año.Contributors_maxs el máximo de contribuidores activos a diario; es decir, de cada semana, cuál fue el número máximo de usuarios que realizaron contribuciones, en un solo día de esa semana. Los contribuidores no son deberían ser sumados, porque es posible —de hecho es probable— que muchos hayan estado activos varios días de una misma semana.Modified_elements_sumes la suma de elementos modificados semanalmente. Pueden existir elementos repetidos en esta suma —cualquier elemento OSM puede ser modificado infinitas veces— pero se consideró que la suma es la función adecuada, pues cada modificación representa una versión diferente del mismo objeto.Created_elements_sumes la suma de elementos creados semanalmente. En este caso sí es correcto aplicar la suma porque cada elemento es creado solamente una vez; en este análisis no se observarán los elementos eliminados.
Es importante mencionar que OSMstats reporta información desde noviembre de 2011, si bien
la historia de OpenStreetMap se remonta a 2004. Por ende, no todas las contribuciones
pueden ser cuantificadas con esta fuente de datos —en Ecuador también había datos antes
de 2011— aunque más del 75 % de las contribuciones sí están disponibles. Ahora el primer
paso es leer el dataset; utilizaremos library(tidyverse) a lo largo del análisis.
Ecuador = read_csv("ecuador_osmstats_2021_week_14.csv") %>%
mutate(Created_elements_cum = cumsum(Created_elements_sum),
Week_after = Week > as.Date("2016-04-16")) %>%
relocate(Week, Week_after)En este paso también se anadió dos nuevas variables: Week_after, un vector
lógico que es TRUE en las observaciones que ocurrieron después del terremoto; y
Created_elements_cum, la suma acumulativa de Created_elements_sum, i.e. el
total estimado de elementos creados (ignorando los eliminados) en el territorio
ecuatoriano. Observemos una muestra de los datos, correspondientes al periodo
del 4 de abril al 29 de mayo de 2016:
filter(Ecuador, Week > as.Date("2016-04-03"), Week < as.Date("2016-05-30")) %>%
mutate(across(Week, as.character, format = "%b.%d")) %>% knitr::kable() %>%
kableExtra::scroll_box(width = "auto", extra_css = "margin-bottom:2rem;")| Week | Week_after | Contributors_max | Modified_elements_sum | Created_elements_sum | Created_elements_cum |
|---|---|---|---|---|---|
| Apr.04 | FALSE | 37 | 11134 | 9852 | 2955785 |
| Apr.11 | FALSE | 92 | 14065 | 96743 | 3052528 |
| Apr.18 | TRUE | 779 | 284127 | 1910560 | 4963088 |
| Apr.25 | TRUE | 240 | 134601 | 691181 | 5654269 |
| May.02 | TRUE | 109 | 66039 | 242967 | 5897236 |
| May.09 | TRUE | 95 | 22999 | 111833 | 6009069 |
| May.16 | TRUE | 73 | 27739 | 90811 | 6099880 |
| May.23 | TRUE | 51 | 36895 | 32570 | 6132450 |
Los resultados de Mapping Ecuador están plasmados en las tres semanas en las cuales se creó más de 200 mil elementos. Interpretando estas observaciones entenderemos que, hasta el domingo 17 de abril de 2016, se creó alrededor de 3.052 millones de elementos; mientras que, hasta el domingo 8 de mayo, esta cifra creció a 5.897 millones. Estamos verificando que se efectuó un esfuerzo formidable: en un periodo de tres semanas, el número de elementos creados en cuatro años (desde noviembre de 2011) prácticamente fue duplicado.
Modelos lineales para la tasa de contribución
Tal vez la manera más directa de evaluar la influencia que Mapping Ecuador pudo haber tenido en las contribuciones OSM es estimar la tasa o velocidad con que estas ocurrieron. Por eso ajustamos una regresión lineal donde la suma acumulativa de elementos creados es la variable dependiente, y el tiempo la independiente; la pendiente de esta regresión es la tasa de contribución. A continuación presento el comando y el gráfico —las observaciones azules son antes del terremoto, las rojas después— correspondientes al cálculo de la regresión lineal:
Model_single = lm(Created_elements_cum ~ Week, Ecuador)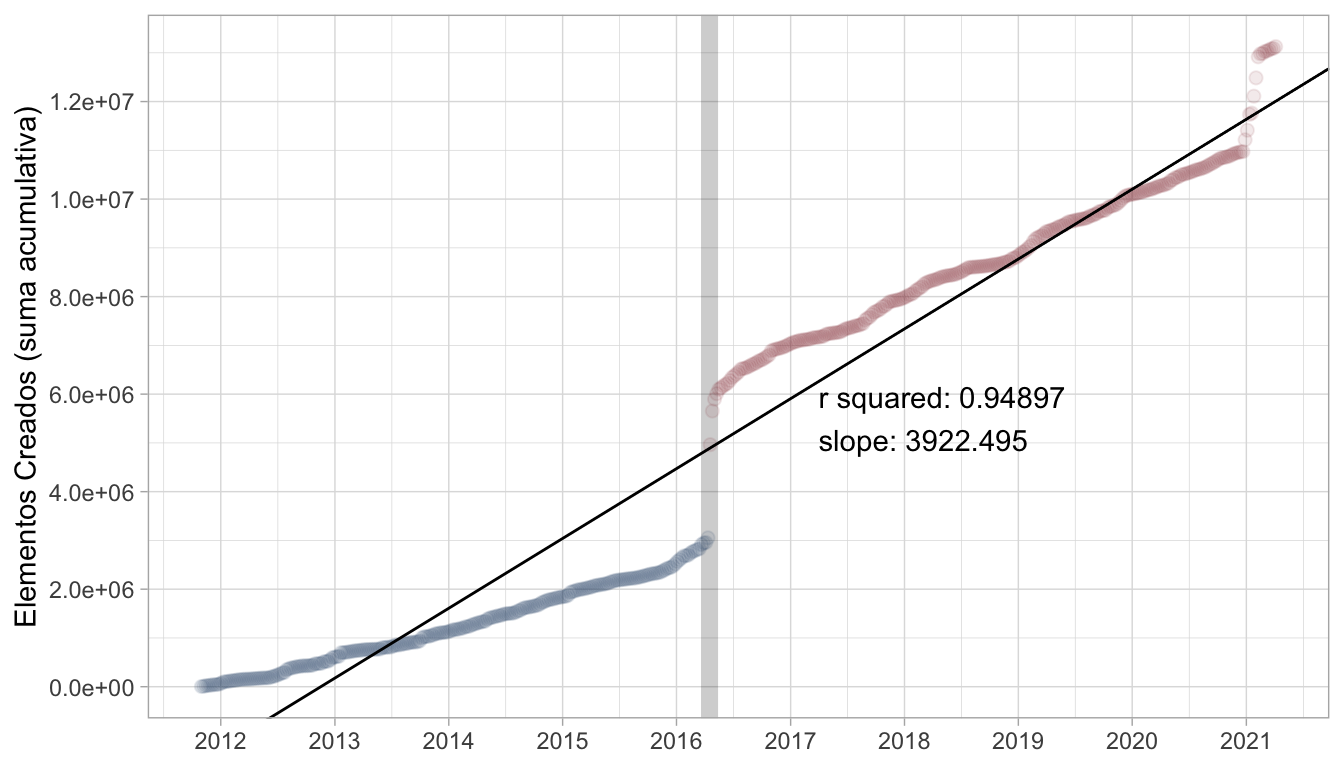
Figure 1: Regresión lineal de contribuciones OSM en Ecuador
En el gráfico observamos dos periodos en los que claramente hubo desviaciones del crecimiento lineal: el primero, por supuesto, es justo después del terremoto; el segundo ocurrió recientemente, al inicio de 2021. De todas maneras la regresión lineal tiene buen ajuste, con un R2 ≈ 0.95, y sugiere que en territorio ecuatoriano se crearon unos 3900 elementos a diario3, desde noviembre de 2011.
Como siguiente paso, para evaluar si Mapping Ecuador influyó en la tasa de contribución, ajustamos
dos regresiones: una para el periodo anterior al terremoto, y otra para el periodo posterior.
En este paso, la variable Week_after es la condición que permite dividir ambos periodos.
Model_before = lm(Created_elements_cum ~ Week, filter(Ecuador, !Week_after))
Model_after = lm(Created_elements_cum ~ Week, filter(Ecuador, Week_after))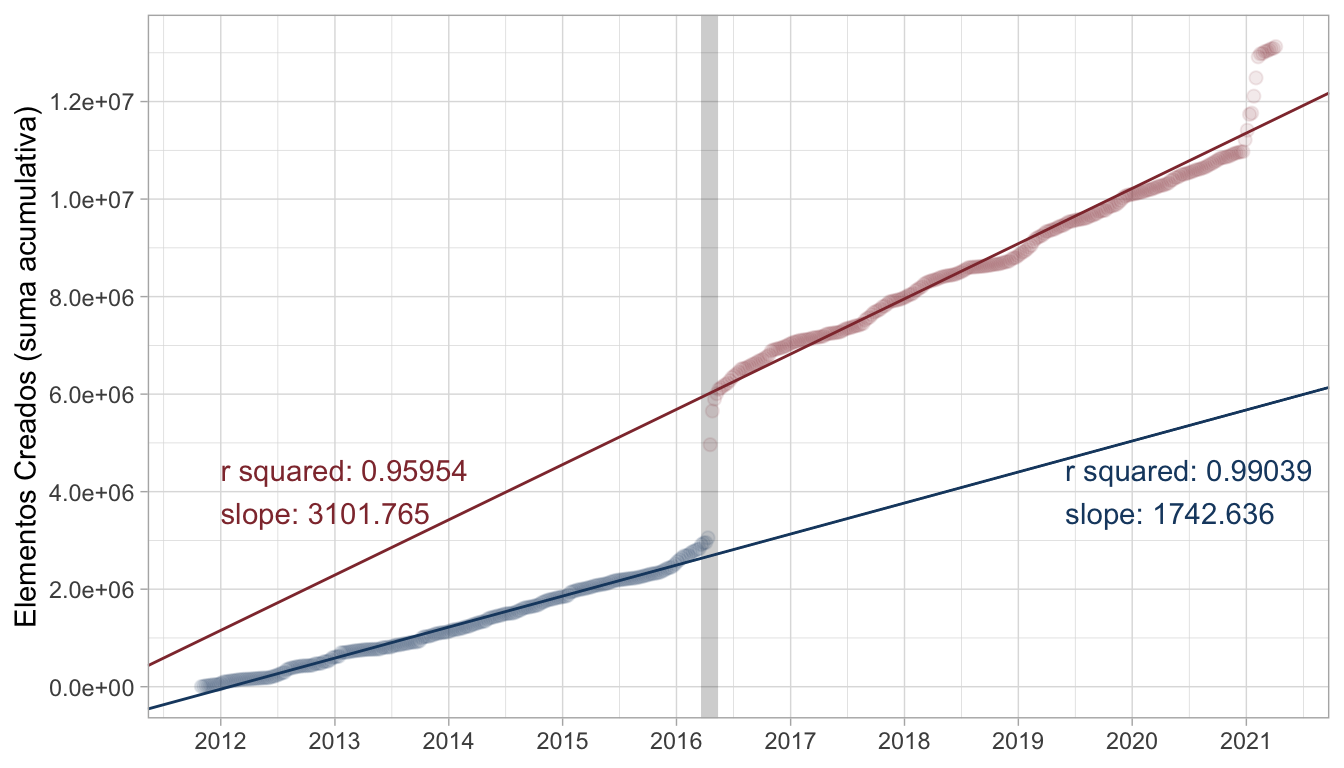
Figure 2: Regresiones lineales de contribuciones OSM en Ecuador, antes y despues del terremoto
Hay una mejora en el ajuste, con ambos R2 > 0.95, aunque esta no es la razón para afirmar que dos regresiones son mejor que una. La razón es que, al dividir las observaciones según ocurrieron antes o después del terremoto, se obtienen dos pendientes notablemente diferentes. Parece que antes del terremoto había una comunidad que contribuía aproximadamente 1700 elementos al día; después del terremoto hay 3100 elementos creados a diario, 1.78 veces la cifra anterior. En este punto sería tentador afirmar que, gracias al esfuerzo de Mapping Ecuador, no solo mejoró la cartografía, sino que también aumentó la tasa de contribución en todo el país.
Sin embargo tal afirmación sería difícil de sostener; hay que considerar algunos factores. Primero, no sabemos si quienes contribuyeron en Mapping Ecuador siguen activos. Más adelante visitaremos este aspecto pero, básicamente, es complicado —de cierta manera, también es irrelevante— saber si los mismos usuarios siguen activos, o si los usuarios actuales son nuevos. Segundo, la regresión es una generalización; su pendiente debe verse como una tendencia a través de los años y no como una constante de la comunidad que contribuye. Y tercero, es posible que el aumento de la pendiente se deba simplemente a que ahora hay más usuarios o más objetos que mapear.
Si bien no entendemos todos los factores involucrados, sí es verdad que la tasa de contribución es más alta en el periodo posterior a Mapping Ecuador. Esto es verdad porque las dos regresiones del gráfico 2 poseen pendientes cuya diferencia es estadísticamente significativa. ¿Cómo se demuestra esto? Volviendo a ajustar una regresión para todo el dataset, como la del gráfico 1, añadiendo esta vez dos nuevas variables independientes: una condición (antes o después del terremoto), y una interacción4 de dicha condición con el tiempo. En lenguaje R, la interacción entre dos variables se escribe multiplicándolas:
lm(Created_elements_cum ~ Week + Week * Week_after + Week_after, Ecuador) %>%
broom::tidy() %>% knitr::kable(format.args = list(scientific = TRUE)) %>%
kableExtra::scroll_box(width = "auto", extra_css = "margin-bottom:2rem;")| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -2.678e+07 | 5.606e+05 | -4.777e+01 | 0e+00 |
| Week | 1.743e+03 | 3.483e+01 | 5.004e+01 | 0e+00 |
| Week_afterTRUE | -1.964e+07 | 7.691e+05 | -2.554e+01 | 0e+00 |
| Week:Week_afterTRUE | 1.359e+03 | 4.567e+01 | 2.976e+01 | 0e+00 |
La tabla demuestra que todos los términos de la regresión son significativos (todos los
p–value ≈ 0). Los términos Intercept y Week_after no nos interesan. Week (el tiempo) es
el término que representa la pendiente y fue estimado en 1743, igual que la regresión azul del
gráfico 2. Y si a este valor sumamos la estimación de Week:Week_after
(la interacción con el tiempo) obtenemos 3102, la pendiente de la regresión roja. Lo que
acabo de explicar puede resultar confuso; para comprender estos conceptos, recomiendo un
artículo de Jim Frost
sobre la comparación de regresiones lineales.
Contribuciones a lo largo del tiempo
A continuación vamos a explorar los elementos creados por semana (no la suma acumulativa
de los mismos), así como los elementos modificados y los contribuidores activos. Antes
de graficar estas variables, podemos anticipar un montón de líneas irregulares pues, salvo
durante un evento como Mapping Ecuador, las observaciones de cada semana no guardan relación
con sus vecinas. Existen varias maneras de suavizar estas irregularidades; en este caso
calculamos la media móvil —usando una ventana de nueve semanas— de cada variable
con zoo::rollmean() y la añadimos al gráfico (las líneas transparentes representan
los datos; las opacas, las medias móviles).
Ecuador_rollmean = mutate(Ecuador, across(3:5, zoo::rollmean, 9, NA))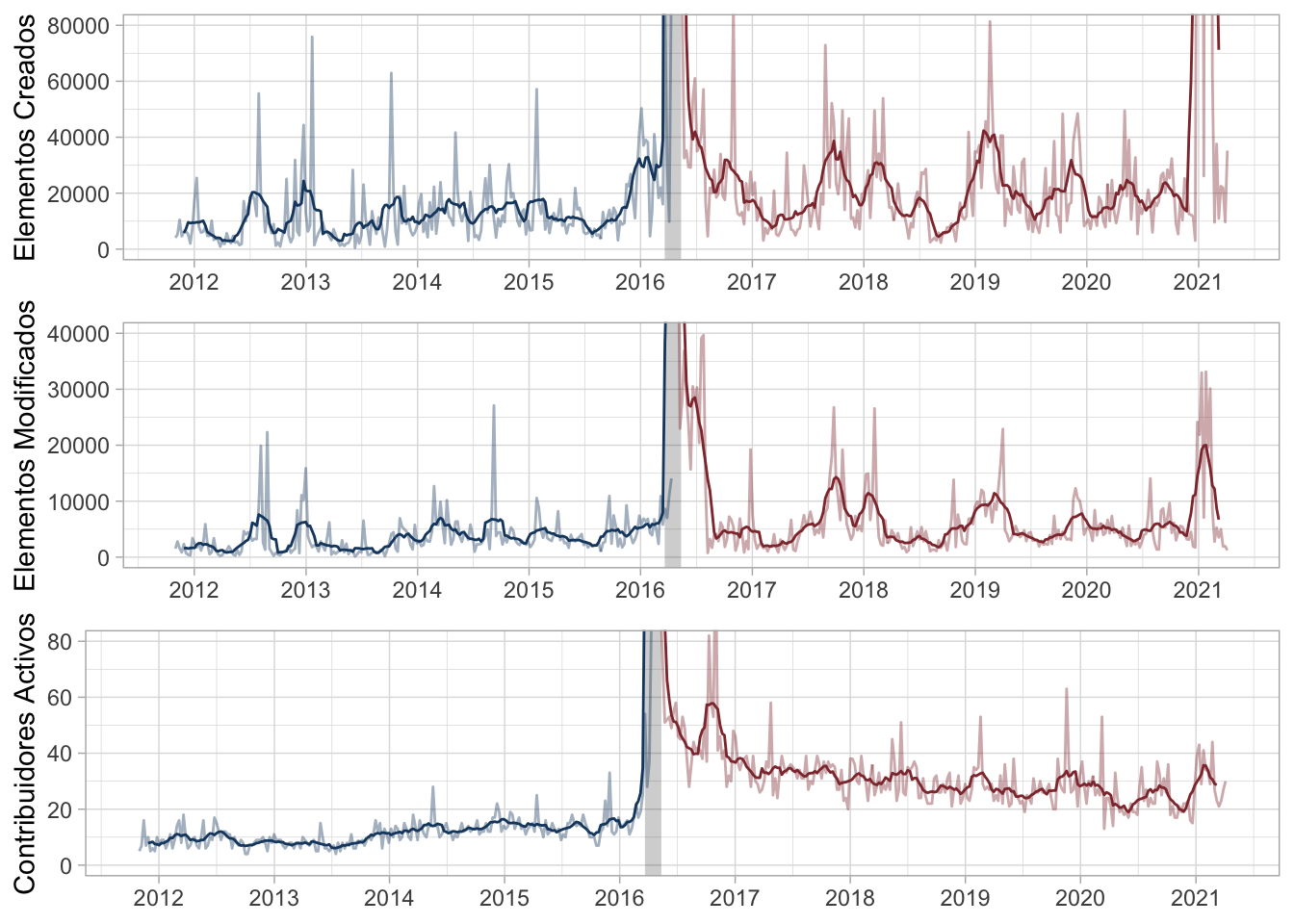
Figure 3: Elementos creados y modificados, y contribuidores activos semanalmente en Ecuador
El resultado más interesante se observa en los contribuidores activos, cuyo máximo semanal es consistentemente mayor después del terremoto. Nuevamente, no sabemos si esto se debe solo a Mapping Ecuador, pero sí sabemos que ahora más usuarios —al menos veinte por semana— están contribuyendo al país. Con respecto a elementos creados o modificados, la media móvil sugiere que en ciertos periodos post–terremoto hubo más actividad de lo normal. Especialmente, en un periodo a inicios de 2021, se superó los 80 mil elementos creados por semana; este hecho solo había ocurrido antes durante Mapping Ecuador. ¿Es posible que otro evento de contribución haya sido organizado? Esta interrogante merece que investigue ese hecho en el futuro.
El gráfico 3 no es tan difícil de interpretar, pero podríamos prescindir de las irregularidades que las líneas causan. Podemos hacer un resumen anual de las mismas variables utilizando boxplots, pero presentaremos únicamente los años con observaciones completas, i.e. de 2012 a 2020.
Ecuador = mutate(Ecuador, Week_after = Week > as.Date("2016-01-01")) %>%
filter( ! as.character(Week, "%g") %in% c("11", "21"))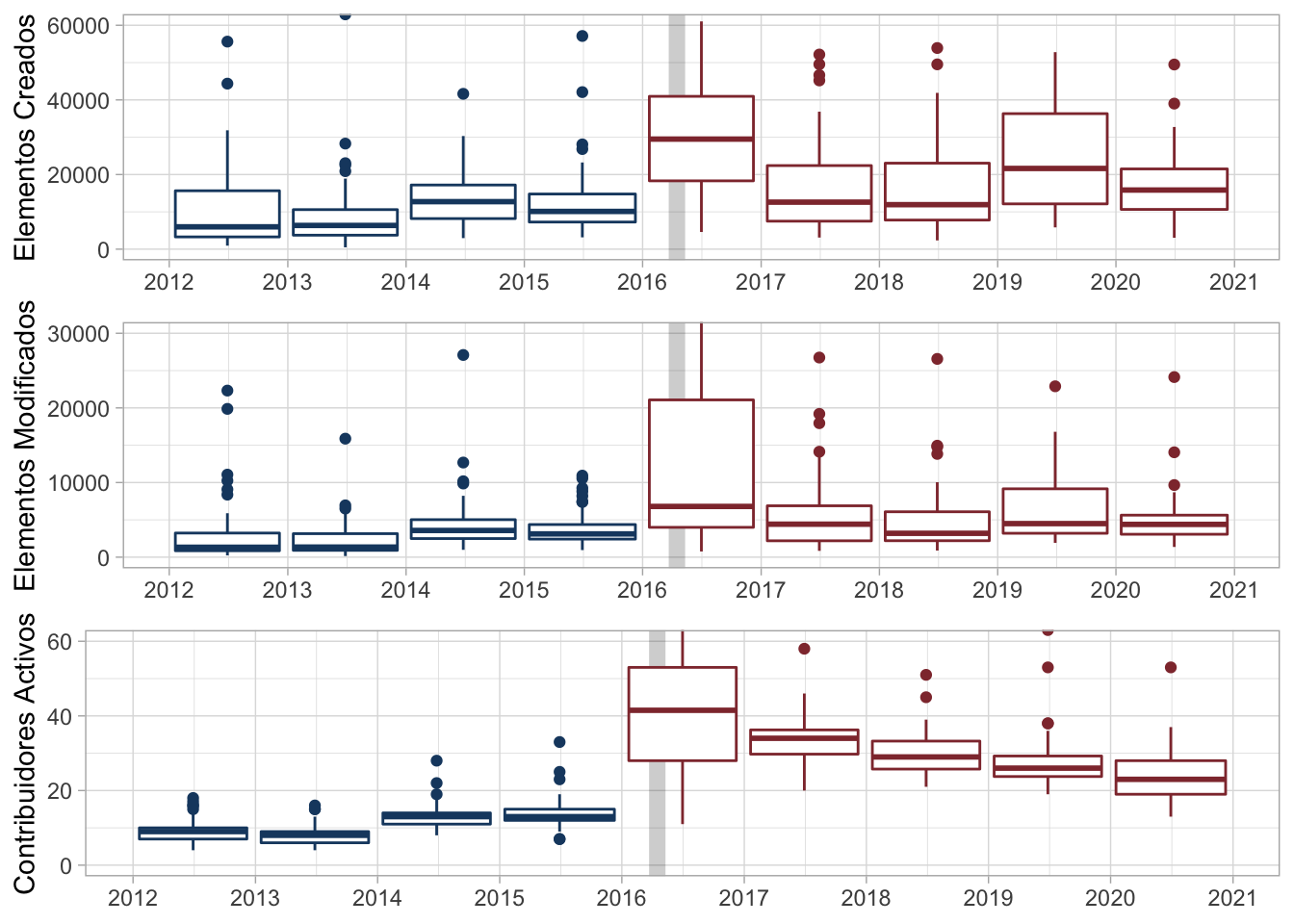
Figure 4: Elementos creados y modificados, y contribuidores activos en Ecuador, agregados anualmente
Aquí debemos mencionar que unos cuantos valores atípicos fueron recortados al limitar los ejes verticales. El aumento de contribuidores activos (en comparación a antes de 2016) también aparece en los boxplots, pero también es evidente que ha habido una disminución progresiva desde ese pico en 2016. Por otra parte, con respecto a elementos creados, los boxplots de 2017 en adelante poseen mediana mayor e IQR más amplio; parece que sí hay una tendencia a más contribuciones, aunque estas ocurran en periodos irregulares (gráfico 3). Resultaría interesante investigar si esos periodos encierran los esfuerzos de una comunidad organizada.
Datos Overpass
Como mencioné al principio del artículo, dos fuentes de datos fueron utilizadas para analizar las contribuciones a Mapping Ecuador. La segunda fuente fue Overpass, una API de solo–lectura que entrega extractos específicos de la base de datos OSM, solicitados a través de queries (consultas). Estas queries son construidas con el Overpass Query Language, el cual es tan poderoso y lleno de funcionalidades, que una introducción a este lenguaje merecería su propio artículo. Por lo pronto, presento la query que usé: esta devuelve todos los elementos creados o modificados en Ecuador, entre el 17 de abril5 y el 9 de mayo de 2016:
[out:csv(::id,::user,::timestamp,::otype,::lat,::lon)];
is_in(0,-80); area._[admin_level=2]; nwr(area._);
nwr._(changed:"2016-04-17T00:00:00Z","2016-05-09T00:00:00Z");
out meta;El sitio web de Overpass ofrece un formulario donde uno
puede insertar esta query y enviarla a la API, la cual devuelve6 un archivo interpreter con valores separados por tabulaciones. Cuando
realicé este proceso, el archivo que recibí tuvo un peso de 167.54 MB y por esta razón
no lo he compartido; el código que utilicé para leerlo es:
Overpass = read_tsv("interpreter", col_types = c("_cTnnn")) %>%
rename_with(str_remove, pattern = "@o?") %>%
filter(timestamp > as.Date("2016-04-17")) %>% arrange(timestamp) %>%
mutate(type = case_when(type==1 ~ "Nodes", type==2 ~ "Ways", type==3 ~ "Relations"))¿Por qué el archivo interpreter es tan pesado? Resulta que contiene 2.751 millones
de elementos creados en el periodo de tres semanas que culminó el 8 de mayo, una cifra
congruente con los datos en la primera tabla de este artículo. De esos elementos, 653
son relations (relaciones), 385 mil son ways (vías) y el resto —la gran mayoría,
como era de esperar— son nodes (nodos). Adicionalmente se identificaron 3731 usuarios diferentes,
pero todavía no consideraremos esta cifra como nuestra estimación del total de contribuidores;
más adelante se verá por qué. Ahora vamos a visualizar los datos en el tiempo y en el espacio.
Contribuciones a lo largo del tiempo
Como sabía que el archivo interpreter no estaría disponible junto con este artículo,
utilicé una estrategia diferente para compartir los datos: leer este archivo, agregar
los datos según el aspecto que está siendo analizado, y escribir un nuevo archivo (mucho
más liviano) con los resultados. Así, para analizar los elementos creados a lo largo del
tiempo, se creó intervalos de doce horas con ayuda de lubridate::ceiling_date() y se
contó los elementos por tipo en cada interavalo:
filter(Overpass, timestamp < as.Date("2016-05-09")) %>%
mutate(across(timestamp, lubridate::ceiling_date, "12 hours")) %>%
count(timestamp, type, name = "value") %>%
pivot_wider(timestamp, type, values_fill = 0) %>%
write_csv("ecuador_overpass_2016_by_time.csv")También se filtró los datos hasta antes del 9 de mayo. Parece un paso redundante (precisamente
se solicitó datos hasta esa fecha), pero resulta que la variable timestamp guarda la fecha
y hora de la última vez que el elemento fue modificado. Entonces, aquellos elementos creados
durante Mapping Ecuador que hayan sido modificados en cualquier momento después del 9 de mayo,
aparecerán aquí con la fecha de modificación.
Este es el caso de alrededor de 131 mil elementos, de los cuales 368 son relations y 25 mil son ways. Esto es una pequeña fracción del total de 2.751 millones de elementos; implica que el 95.26 % de las contribuciones en Mapping Ecuador no han sido modificadas. Sin embargo, este porcentaje cambia drásticamente si diferenciamos por tipo de elemento: solo el 43.64 % de relations no han recibido modificaciones. Tiene sentido, pues estos son los elementos OSM más complejos y menos estáticos.
El archivo ecuador_overpass_2016_by_time.csv
se puede leer fácilmente con readr::read_csv(); a continuación se encuentra el gráfico con sus observaciones.
Overpass_by_time = read_csv("ecuador_overpass_2016_by_time.csv")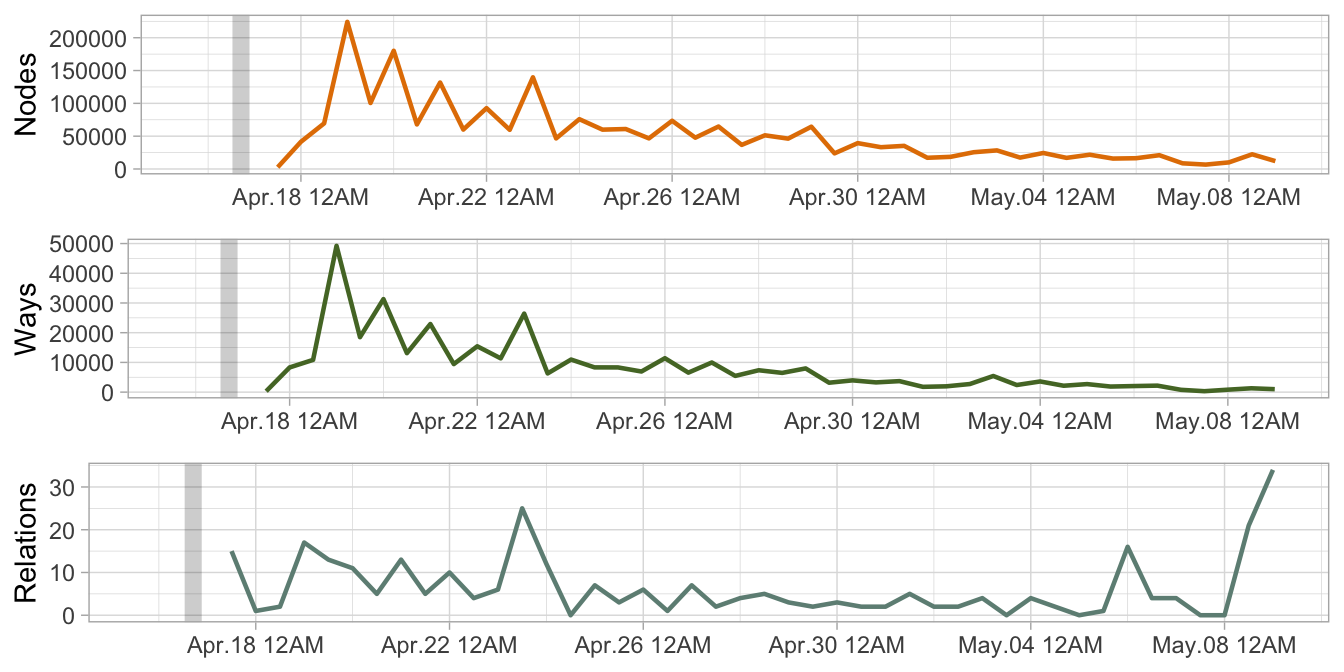
Figure 5: Conteo de elementos contribuidos en Mapping Ecuador, en intervalos de doce horas
El gráfico revela como hasta el 23 de abril, una semana después del terremoto, aparecieron la mayor cantidad de contribuciones; también revela el ciclo diario de actividad, que es mayor entre las 12 PM y las 12 AM. El número de relations no disminuye progresivamente pero de todas maneras es escaso. En cambio, es interesante como ways y nodes presentan una fuerte correlación; por supuesto esto sucede porque la manera de trazar ways —que permiten representar toda clase de objetos, no solo carreteras— es ubicando nodes.
Contribuciones por usuario
Para analizar los datos con respecto a los usuarios, nuevamente debemos filtrar hasta el 9
de mayo; toda modificación hecha después de esa fecha tendrá, además del nuevo timestamp,
el nombre del usuario que modificó. Estos nombres no necesariamente están relacionados con
Mapping Ecuador y por eso los descartamos, reduciendo a 2762 los usuarios; esta es nuestra
estimación del número de contribuidores al proyecto. Una observación: 175 de los nombres
descartados también figuran entre las contribuciones antes del 9 de mayo; significa que
el 6.34 % de usuarios en Mapping Ecuador han vuelto a modificar elementos del proyecto,
después de que el mismo concluyó. No obstante, no es que este sea el porcentaje que
sigue activo, porque no consideramos toda la actividad en el país.
En el siguiente paso se cuenta los elementos, por tipo y por usuario, y se escribe los resultados en el archivo
ecuador_overpass_2016_by_user.csv:
filter(Overpass, timestamp < as.Date("2016-05-09")) %>%
count(user, type, name = "value", sort = TRUE) %>%
pivot_wider(user, type, values_fill = 0) %>%
write_csv("ecuador_overpass_2016_by_user.csv")Manipulando estas observaciones es posible descubrir que, del total de 2762 usuarios, solamente 47 contribuyeron diez mil elementos o más cada uno; son pocos, pero sumando sus aportes alcanzan la cifra de 1.120 millones, lo que es el 42.76 % de todo Mapping Ecuador. Es más, los doce usuarios más activos —cada uno contribuyó más de 33 mil elementos— son responsables de 529 mil elementos, o el 20.18 % del total. En otras palabras: doce personas crearon o modificaron más de medio millón de elementos, una quinta parte del proyecto. Este hecho es típico en proyectos colaborativos abiertos: unos cuantos usuarios realizan gran parte del trabajo, y la mayoría aportan un poco. Los aportes de la mayoría son, sin embargo, lo que logra que el proyecto sea exitoso.
En este punto decidí visualizar las contribuciones de los doce usuarios más activos, experimentando
con waffleplots: una clase de gráficos que presentan el conteo de una variable —en este caso,
miles de nodes y ways creados— de una manera intuitiva. Utilicé el paquete waffle con la
precaución de instalarlo vía remotes::install_github("hrbrmstr/waffle") pues es en la última
versión donde se encuentrageom_waffle(), la geometría que permite graficar waffleplots.
Overpass_by_user = read_csv("ecuador_overpass_2016_by_user.csv") %>%
filter(Nodes + Ways + Relations > 33e3) %>%
mutate(across(Ways:Nodes, ~ round(. / 1e3) )) %>%
pivot_longer(Ways:Nodes)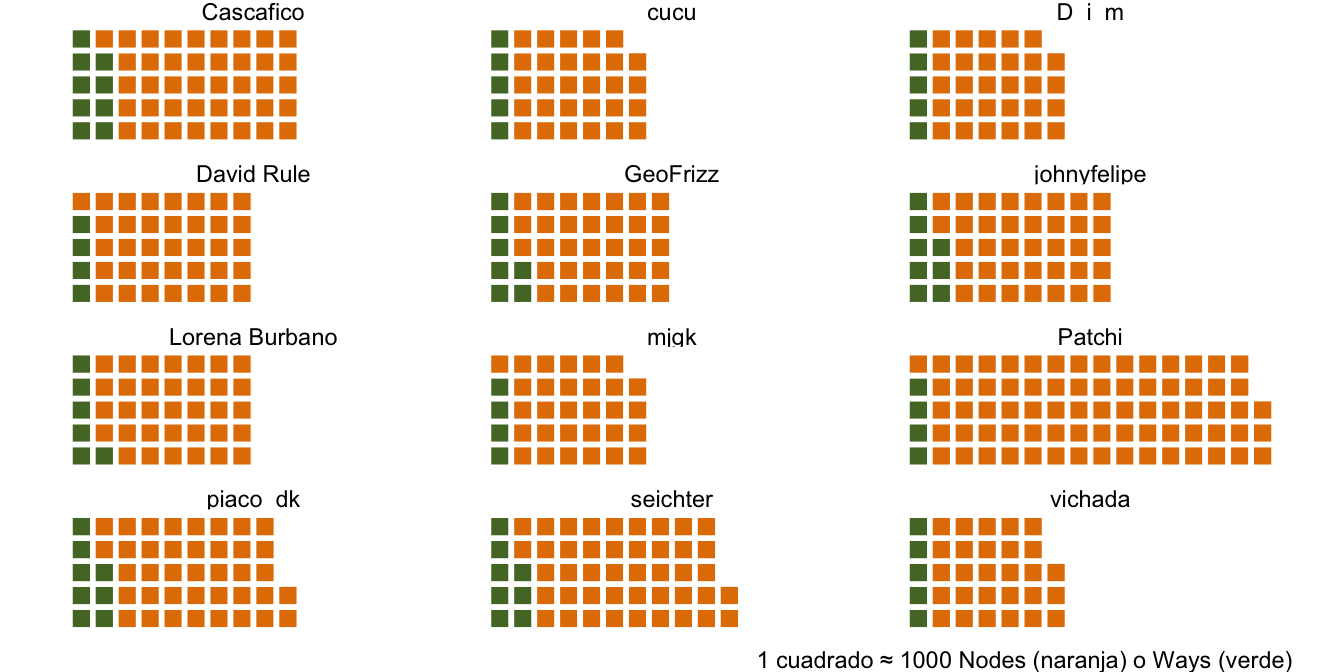
Figure 6: Waffleplots de elementos contribuidos por los doce usuarios mas activos en Mapping Ecuador
Contribuciones en el espacio
Finalmente, para analizar el aspecto espacial no es necesario retirar las modificaciones posteriores al 9 de mayo porque es improbable que haya cambiado la ubicación de los elementos. En cambio, se deben retirar ways y relations, porque solamente los nodes poseen coordenadas definidas a través de latitud y longitud. Los otros elementos se componen de varios nodes así que no poseen una sola coordenada; más bien poseen un bounding box que puede ser calculado utilizando funcionalidad avanzada del Overpass Query Language, pero esto no fue solicitado. De cualquier forma, los nodes son el 85.97 % de los elementos, así que podremos graficar la distribución espacial sin problemas.
filter(Overpass, type == "Nodes") %>%
mutate(across(lat:lon, round, digits = 1)) %>%
count(lat, lon, name = "Nodes") %>%
write_csv("ecuador_overpass_2016_by_lat_lon.csv")En ecuador_overpass_2016_by_lat_lon.csv
tenemos el conteo de nodos por celda de 0.1º de latitud y 0.1º de longitud. Estos datos
pueden transformarse en un objeto espacial usando sf::st_as_sf() con el código
EPSG 4326 (i.e. coordenadas sin proyectar en el dátum WGS 84). Así es como generé
este heatmap (mapa de calor) de nodes contribuidos en Mapping Ecuador; podemos
observar el resultado de este enorme proyecto en las celdas con más de diez
mil nodes, extendiéndose desde Manta hasta Esmeraldas.
Overpass_by_lat_lon = read_csv("ecuador_overpass_2016_by_lat_lon.csv") %>%
mutate(Nodes = cut(Nodes, c(1, 100, 1e3, 1e4, 24e4), include.lowest = TRUE)) %>%
filter(lon >= -81) %>% sf::st_as_sf(coords = c("lon", "lat"), crs = "EPSG:4326")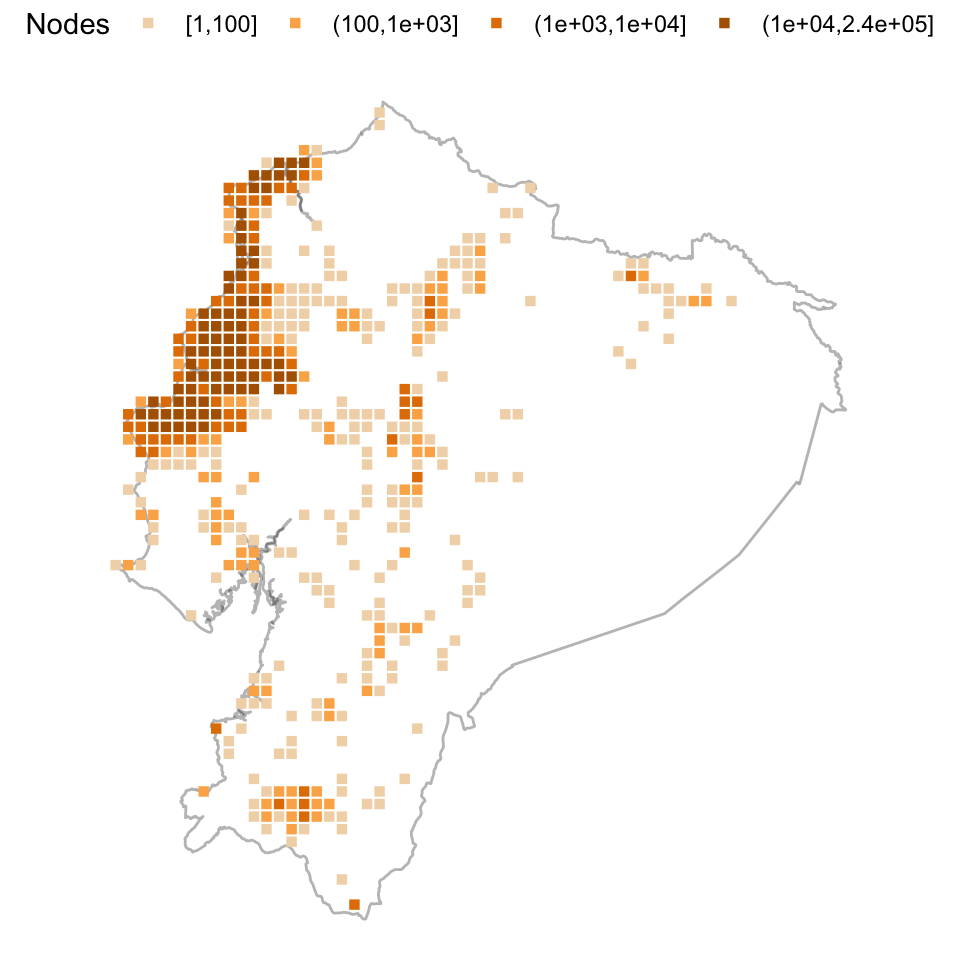
Figure 7: Heatmap de nodos contribuidos durante Mapping Ecuador
Comentarios
Goodchild (2007), al acuñar el término Volunteered Geographic Information (VGI) para referirse a proyectos como OpenStreetMap, identificó que la gestión de emergencias sería en el futuro uno de los escenarios en donde las ventajas de la VGI resultarían más beneficiosas. El terremoto 16A y otros desastres atendidos por el HOT dan testimonio de esto. Según Goodchild, dichas ventajas —e.g. que la información se genera rápidamente— se derivan de datos levantados in situ por personas locales; pero en la práctica, esto no siempre ocurre. Muchos objetos ingresan al mapa al ser dibujados por un usuario remoto, a partir de imágenes satelitales. En Mapping Ecuador se utilizó esta estrategia: el sitio web de LLACTALAB registra eventos de mapeo en España y Estados Unidos.
Aunque la información extraíble de una imagen satelital es limitada, esta clase de contribuciones no deben ser desalentadas, especialmente en una situación de emergencia. Sin embargo, es verdad que la información levantada localmente difiere de la remota no solo en calidad, sino en los objetos que son creados. Quinn (2016) observó que varios lugares en Sudamérica —uno de los continentes con menos usuarios OSM— han sido mapeados remotamente, pero en los lugares donde la contribución es local abundan los objetos relacionados con la vida cotidiana, como escuelas, hospitales y tiendas. Estos objetos hacen que el mapa sea más valioso para sus usuarios y por eso son una parte crucial del mismo; a pesar de este hecho, en este artículo no analicé la cantidad de contribución local.
Mi propósito fue contabilizar y graficar varios aspectos de Mapping Ecuador, no identificar el origen de las contribuciones. Eso sería virtualmente imposible, pues muy pocos usuarios —especialmente entre aquellos que no son europeos— han creado un perfil con información personal (Quinn 2016). OpenStreetMap es un proyecto que se beneficia enormemente del altruismo; no es de extrañar que abunde el anonimato. Por esta razón afirmé que es irrelevante tratar de averiguar quiénes siguen activos y quiénes no: porque estas personas actuaron con solidaridad, porque más grande es la obra que los nombres. Como conclusión, ¿afirmaremos que Mapping Ecuador aumentó la actividad en el país? Para ser que sí, pero lo importante es que fue una iniciativa valiosa y oportuna.
Este análisis lo conduje antes, para el Open Data Day 2020; mi propósito también es identificar nuevos aspectos.↩︎
OSMstats advierte que la manera de averiguar a qué país pertenecen las contribuciones es calcular el centro del changeset, lo cual puede causar del 2 al 10 % de inexactitud.↩︎
La tasa es diaria, a pesar de que las observaciones son semanales, porque el día es la unidad de cálculo de fechas.↩︎
En estadística, una interacción ocurre cuando la relación entre dos variables depende de una tercera, en este caso la condición. La interacción causa que, cuando cambia la condición, cambie también la pendiente de la regresión.↩︎
Overpass interpreta las horas en UTC así que, como en la query se especifica las 00:00 del 17 de abril, esto corresponde en Ecuador a las 19:00 del 16 de abril; es decir, justo después del terremoto.↩︎
La manera de “recibir” el archivo
interpreterdepende del navegador. Lo he intentado en Chrome, que lo descarga automáticamente, y en Safari, que lo abre en una pestaña. Considere esto porque es un archivo pesado.↩︎