Mejorando nuestro Web Scraping
En este artículo vamos a enmendar la metodología web scraping que utilizamos
anteriormente para obtener, desde OSMstats, los
nodos OpenStreetMap creados a diario en cada país. Neis Pascal, quien mantiene ese
sitio web, introdujo el año pasado algunas mejoras que ahora impiden la ejecución de
get_day(),
la función que diseñamos para este fin. Aprovechamos esta ocasión para introducir
el paquete rvest, que simplificará y acelerará todo el proceso; adicionalmente,
cuantificaremos con benchmarks la magnitud de la mejora.
En get_day() se utilizaba httr para conectarse a la página web —que en realidad
se trata de un documento HTML— deseada y obtener su contenido. Los objetos generados
por httr::content() son de clase xml_document.
osmstats = "https://osmstats.neis-one.org/?item=countries&date=1-3-2021"
(httr_doc = httr::content(httr::GET(osmstats), "parsed", encoding = "UTF-8"))## {html_document}
## <html xmlns="http://www.w3.org/1999/xhtml" lang="en">
## [1] <head>\n<title>OSMstats - Statistics of the free wiki world map</title>\n ...
## [2] <body>\n\t\n<script language="javascript">function weekendArea(axes) {var ...Un xml_document es como una copia de la página en linea, con exactamente la misma
estructura de tags1. En el sitio OSMstats existe una página para cada día —desde
el primero de noviembre de 2011— con la actividad suscitada en 260 territorios del mundo.
Nos interesa extraer de cualquiera de esas páginas (es decir, para cualquier día) un tag
de tipo <table>: una tabla con los elementos creados, modificados y eliminados un día
específico. La siguiente captura de pantalla presenta la tabla correspondiente2 al primero de marzo de 2021.
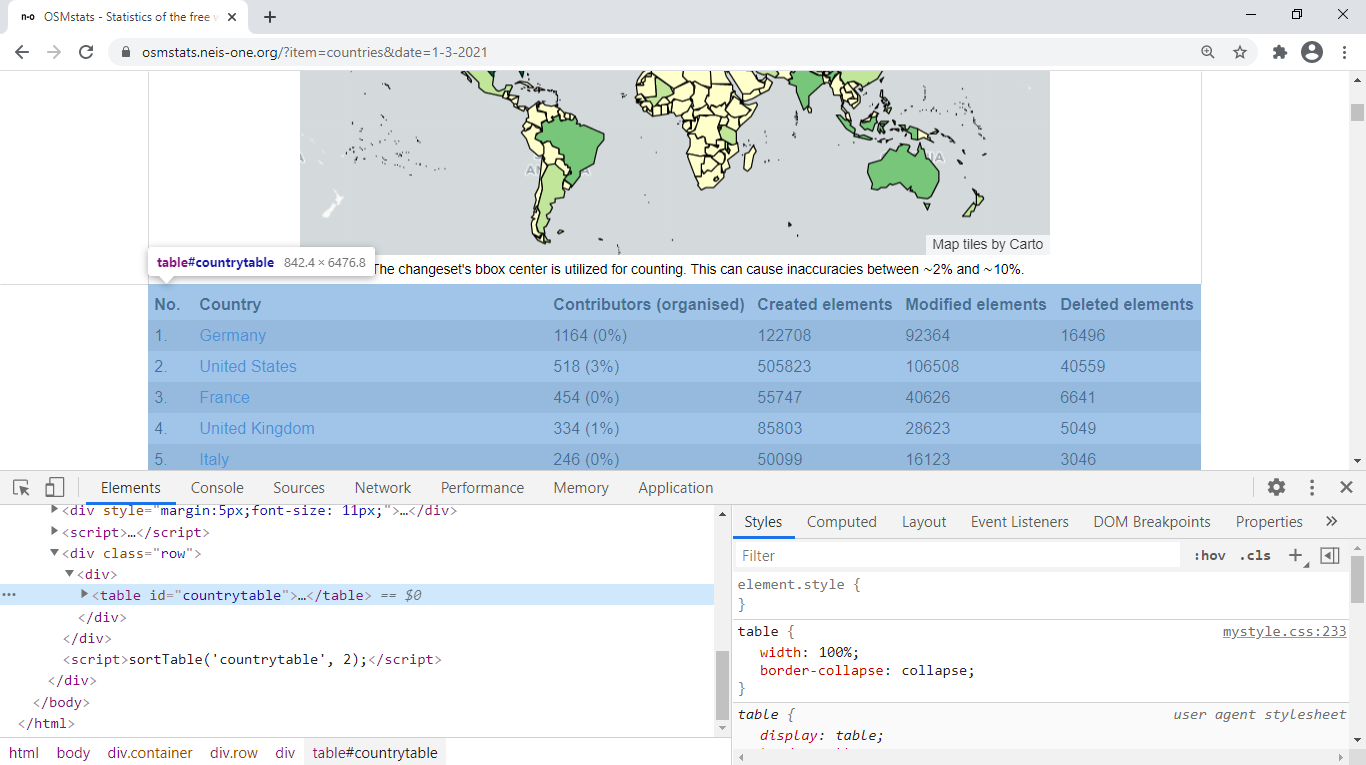
Figure 1: El tag <table> en una página de OSMstats
Originalmente se utilizaba xml2::as_list() para convertir el xml_document en una
típica lista de R; luego, con funciones escritas específicamente para estos propósitos,
se buscaba dentro de la lista el miembro correspondiente al <table>, y se procesaba
cada uno de sus submiembros como filas de una matriz.
pluck_xml = function(x) x$html$body[[12]][[14]]$div$table[-1]
row_xml = function(x) matrix(
c( x[[2]][[1]][[1]], x[[4]][[1]], x[[6]][[1]], x[[8]][[1]], x[[10]][[1]] ), 1)La manera de utilizar estas funciones es la siguiente:
library(purrr)
httr_table = xml2::as_list(httr_doc) %>%
pluck_xml() %>% map(row_xml) %>% reduce(rbind)
table_names = c("country", "contributors", "created_e", "modified_e", "deleted_e")
colnames(httr_table) = table_names; head(httr_table)## country contributors created_e modified_e deleted_e
## [1,] "Puerto Rico" "1 (0%)" "53" "15" "2"
## [2,] "Liberia" "1 (0%)" "9464" "1695" "1852"
## [3,] "Vanuatu" "1 (0%)" "0" "4" "0"
## [4,] "Curaçao" "1 (0%)" "5" "2" "6"
## [5,] "Cape Verde" "1 (0%)" "12" "25" "1"
## [6,] "Mauritius" "1 (0%)" "0" "3" "0"Si el código presentado hasta ahora es difícil de comprender, no importa mucho. A
continuación se demostrará cómo con rvest es posible repetir esas operaciones, de
una manera más sencilla; este paquete está construido sobre httr y xml2, así que
también trabaja con objetos xml_document. Ahora obtendremos el contenido de la página
web deseada vía rvest::read_html().
library(rvest)
rvest_doc = read_html(osmstats, encoding = "UTF-8")
identical(httr_doc, rvest_doc) # documentos obtenidos vía httr y rvest parecen diferentes## [1] FALSE## [1] TRUEUna vez obtenido el documento, es posible extraer el <table> con rvest::html_node().
Esta función ofrece dos opciones para especificar la búsqueda de un tag, que será
devuelto como un objeto xml_node3. La primera opción es
suministrar un selector CSS4 que seleccione (valga la
redundancia) de manera exacta el tag que buscamos.
Observando la captura de pantalla (figura 1), descubriremos que el tag de la
tabla está escrito así: <table id="countrytable">; puesto que es el único tag con ese id
en toda la página —además es la única tabla— podemos utilizar el siguiente selector:
## # A tibble: 260 x 6
## No. Country `Contributors (organis~ `Created element~ `Modified element~
## <dbl> <chr> <chr> <int> <int>
## 1 1 Puerto Ri~ 1 (0%) 53 15
## 2 2 Liberia 1 (0%) 9464 1695
## 3 3 Vanuatu 1 (0%) 0 4
## 4 4 Curaçao 1 (0%) 5 2
## 5 5 Cape Verde 1 (0%) 12 25
## 6 6 Mauritius 1 (0%) 0 3
## 7 7 Oman 1 (0%) 0 3
## 8 8 Jordan 1 (0%) 47 10
## 9 9 Monaco 1 (0%) 0 1
## 10 10 Haiti 1 (0%) 216 201
## # ... with 250 more rows, and 1 more variable: Deleted elements <int>En la última línea de código, el xml_node extraído se introduce inmediatamente
en html_table() y el resultado es un data.frame correspondiente a la tabla con la
actividad OpenStreetMap del día. Y eso es todo: con tres funciones de rvest hemos
simplificado la metodología original. Además, como estas funciones han sido optimizadas,
se ejecutan de manera más rápida. Vamos a realizar un benchmark para cuantificar la
mejora en la rapidez; definimos una función para contener el método de tabulado original,
y otra para el nuevo (parse_old() y parse_rvest() respectivamente):
parse_rvest = function(doc) html_table(html_node(doc, "#countrytable"))[-1]
parse_old = function(doc) as_list(doc) %>% pluck_xml() %>% map(row_xml) %>%
reduce(rbind) %>% as.data.frame() %>% set_names(table_names) %>%
mutate(across(ends_with("_e"), as.numeric))
summary(parse_rvest(rvest_doc) == parse_old(rvest_doc)) # generan tablas iguales## Country Contributors (organised) Created elements Modified elements
## Mode:logical Mode:logical Mode:logical Mode:logical
## TRUE:260 TRUE:260 TRUE:260 TRUE:260
## Deleted elements
## Mode:logical
## TRUE:260E introducimos ambas funciones en microbenchmark():
library(microbenchmark)
(parsing_bmark = microbenchmark(parse_rvest(rvest_doc), parse_old(rvest_doc)))## Unit: milliseconds
## expr min lq mean median uq max neval
## parse_rvest(rvest_doc) 158.4 168.6 173.4 173.4 177.7 188.5 100
## parse_old(rvest_doc) 326.2 354.8 368.2 366.0 377.8 442.6 100boxplot(filter(parsing_bmark, time < 4.5e8),
main = "Table parsing benchmark",
ylab = "Milliseconds")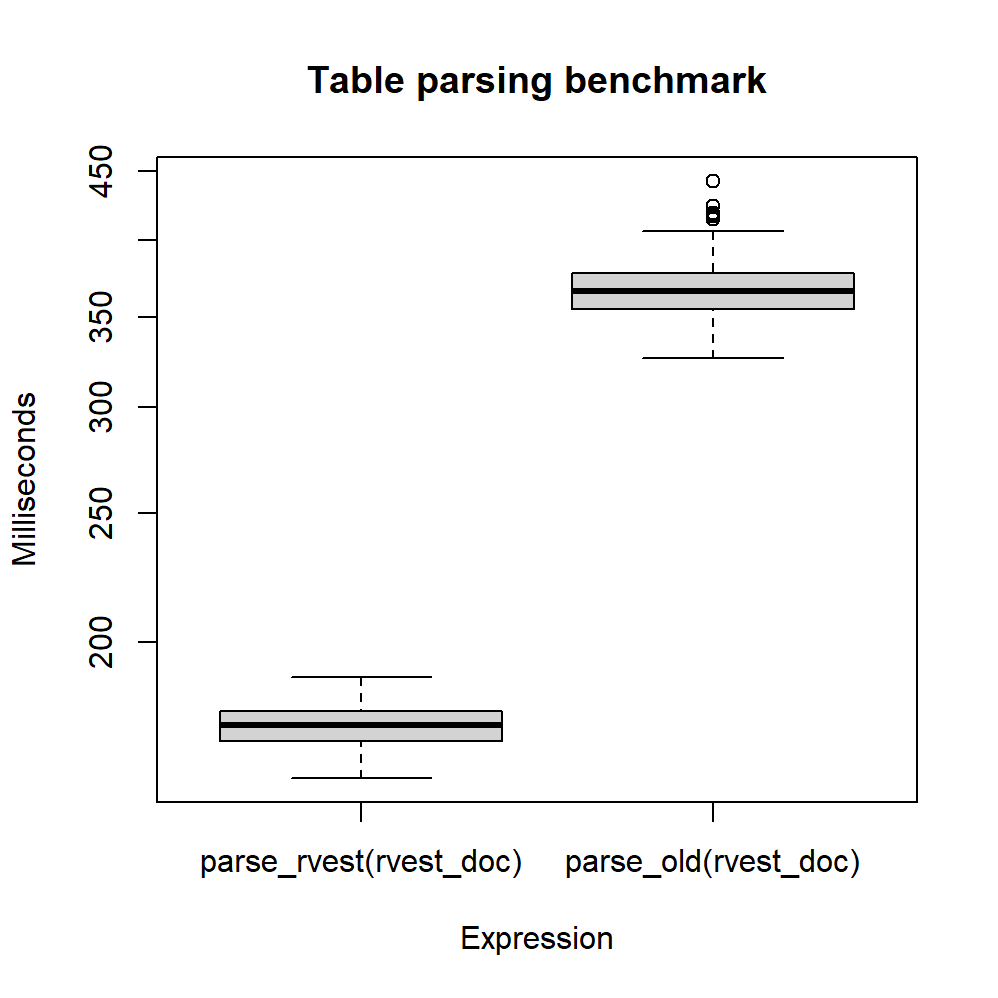
Figure 2: Benchmark de los dos métodos de tabulación
Resulta claro que el nuevo método es considerablemente más rápido que el original: el
tiempo de ejecución se redujo a la mitad (la mediana pasó de 0.37 a 0.17 segundos).
Por ende, a partir de ahora se aprovechará rvest para realizar web scraping; no
obstante, todavía existe un aspecto a través del cual podemos introducir una mejora
en la rapidez de ejecución. Se mencionó que html_node() ofrece dos opciones para
especificar cuál nodo debe ser extraído. La segunda opción es suministrar una
expresión XPath, que funciona
de manera similar a la ruta de un archivo en un computador.
Vamos a comparar la rapidez de extracción con un selector CSS y con dos XPaths. La
expresión "//table" significa buscar una tabla (recordemos que solo hay una en cada
página de OSMstats), sin importar su ubicación dentro del documento; podemos decir que
esta es una expresión “fácil”. Con el otro XPath vamos a especificar exactamente dónde
se encuentra la tabla; esto es comparable a la función pluck_xml() definida en el
método original y será, en teoría, la expresión más rápida.
easy_css = function(doc) html_node(doc, css = "#countrytable")
easy_xpath = function(doc) html_node(doc, xpath = "//table")
exact_xpath = function(doc) html_node(doc, xpath = "body/div[3]/div[4]/div/table")
extraction_bmark = microbenchmark(easy_css(rvest_doc),
easy_xpath(rvest_doc),
exact_xpath(rvest_doc))
boxplot(filter(extraction_bmark, time < 4.5e6),
main = "Table extraction benchmark",
ylab = "Microseconds")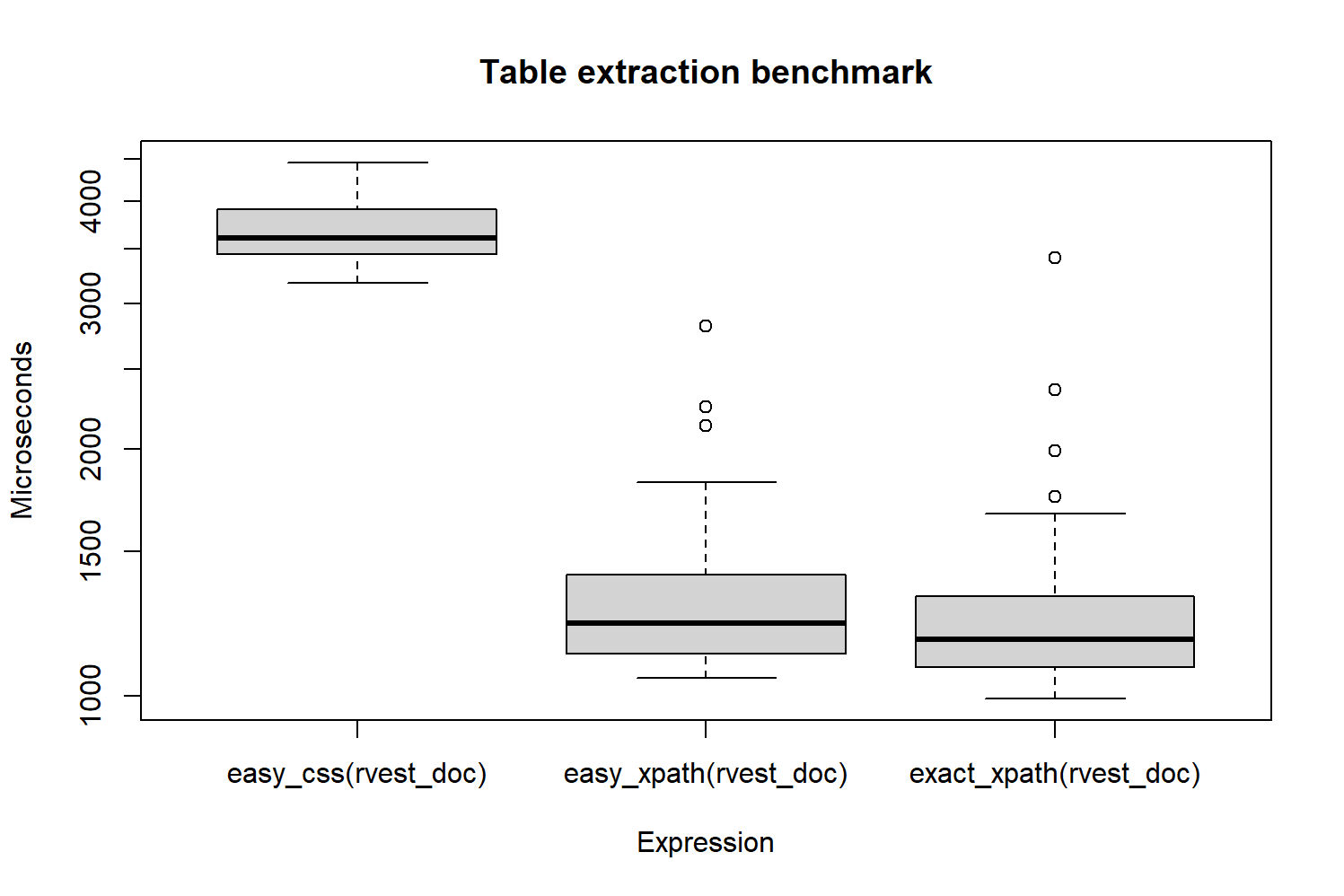
Figure 3: Benchmark de los tres métodos de extracción
El resultado es que la extracción es unos 2 milisegundos más lenta cuando se utiliza
el selector. Cuando se utiliza la expresión XPath exacta existe una pequeña mejora,
comparada con la expresión fácil; sin embargo, dicha mejora se encuentra en el orden
de los microsegundos. Como conclusión, en el futuro —cuando necesitemos obtener
nuevamente los elementos OpenStreetMap creados en un día— usaremos la
expresión "//table" que es igual de rápida y más fácil de comprender.
Los tags son los nodos o elementos que componen a un documento HTML, como
<a>o<tr>.↩︎En realidad, en la pestaña Countries de OSMstats, cada página contiene los datos correspondientes al día anterior; así, en este ejemplo, los datos son del 28 de febrero.↩︎
También existe
rvest::html_nodes()que puede extraer varios tags a la vez y devuelve unxml_nodeset.↩︎Los selectors son reglas para aplicar estilos en un documento HTML, como
a:hover { }otr.odd { }.↩︎