El crecimiento diario de los nodos OSM
En el primer artículo de este blog presenté cómo generar un mapa coroplético de las
contribuciones a OpenStreetMap; utilizando una metodología web scraping fui capaz de
contabilizar el 75 % de los nodos existentes, así que fue una buena estimación inicial.
Con todo, contabilizar los nodos en cada país no constituye un aprovechamiento completo de
esos datos; después de todo, se trata de 738 mil observaciones.
Por eso, ahora estimaremos la tasa de crecimiento de las contribuciones en cada país.
Utilizaremos tidyverse para cargar simultáneamente varios paquetes necesarios.
library(sf)
library(tidyverse) # contiene dplyr, ggplot2, purrr, tidyr
data("World", package = "tmap")
countries = select(st_drop_geometry(World), country = name, continent) %>%
left_join(countries) %>% # el dataset countries viene del primer artículo
filter(date != as.Date("2019-11-01"))En este primer paso se descartó aquellos territorios que no podrán ser representados en el mapa (reduciendo su número de 253 a 173) y también se añadió el continente al que pertenece cada uno. Ahora, la cantidad de observaciones es mayor que la necesaria, esto debido a que la periodicidad es diaria. Una estrategia para reducir la cantidad es “agregar” o agrupar las observaciones utilizando un periodo más largo; así que en el siguiente paso se calculan la suma1 y la suma acumulativa de nodos creados, al final de cada mes.
countries_month = mutate(countries, across(date, lubridate::ceiling_date, "month")) %>%
group_by(continent, country, date) %>%
summarise(nodes_sum = sum(created)) %>%
mutate(nodes_cum = cumsum(nodes_sum), date = date - 1) # el último día de cada mes
head(countries_month)## # A tibble: 6 x 5
## # Groups: continent, country [1]
## continent country date nodes_sum nodes_cum
## <fct> <chr> <date> <dbl> <dbl>
## 1 Africa Algeria 2011-11-30 45598 45598
## 2 Africa Algeria 2011-12-31 60887 106485
## 3 Africa Algeria 2012-01-31 46259 152744
## 4 Africa Algeria 2012-02-29 33228 185972
## 5 Africa Algeria 2012-03-31 24461 210433
## 6 Africa Algeria 2012-04-30 15374 225807Después del agregamiento existen 96 observaciones mensuales para cada territorio. La cantidad de datos ya es adecuada para ajustar un modelo; sin embargo, sigue siendo muy grande como para ser visualizada. Para este gráfico se agregó aún más los datos: calculando el promedio de nodos creados mensualmente en cada continente2, exceptuando la Antártida.
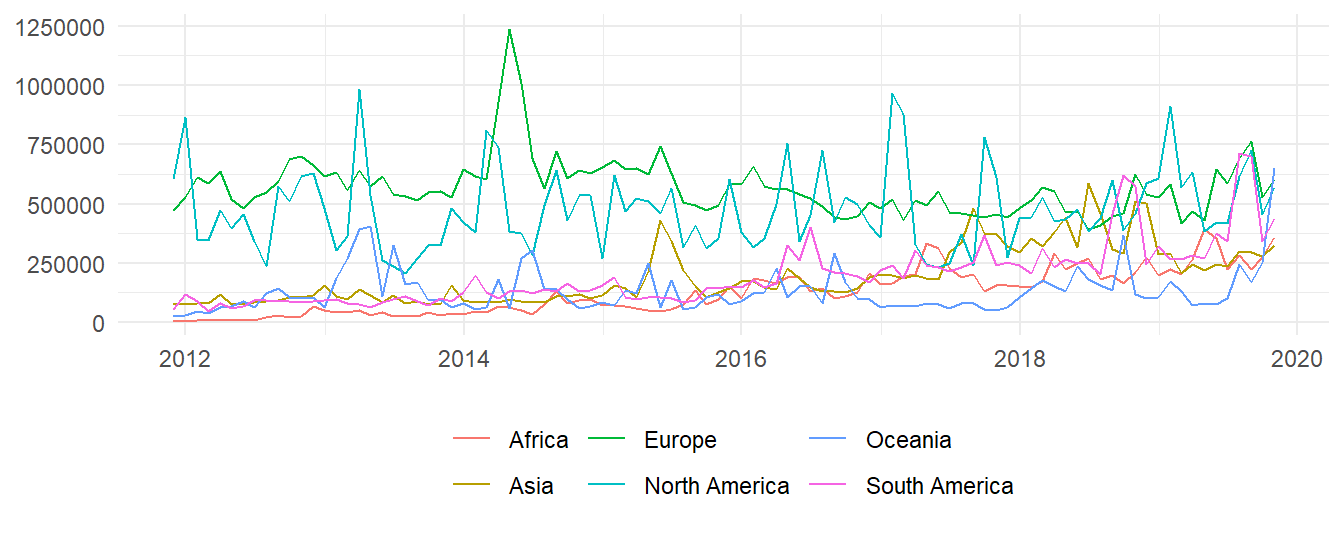
Figure 1: Promedio de nodos creados mensualmente en cada continente
Aquí se verifica el hecho de que, a nivel mundial, los niveles de contribución más elevados ocurren en países europeos. Lo mismo no necesariamente pasa en Norteamérica, pero las contribuciones en Estados Unidos elevan el promedio en ese continente. En África, Asia y Sudamérica la participación ha sido menor, pero incrementando a través de los años. Si quisiéramos trazar la evolución de todos los países, resultaría un gráfico saturado de líneas. En vez de eso se seleccionó, de cada continente, los dos países con más nodos en total; en orden decreciente de nodos, los países son:
- Estados Unidos 🇺🇸
- Rusia 🇷🇺
- Canadá 🇨🇦
- Francia 🇫🇷
- Indonesia 🇮🇩
- Japón 🇯🇵
- Brasil 🇧🇷
- Tanzania 🇹🇿
- Australia 🇦🇺
- Nigeria 🇳🇬
- Nueva Zelanda 🇳🇿
- Argentina 🇦🇷
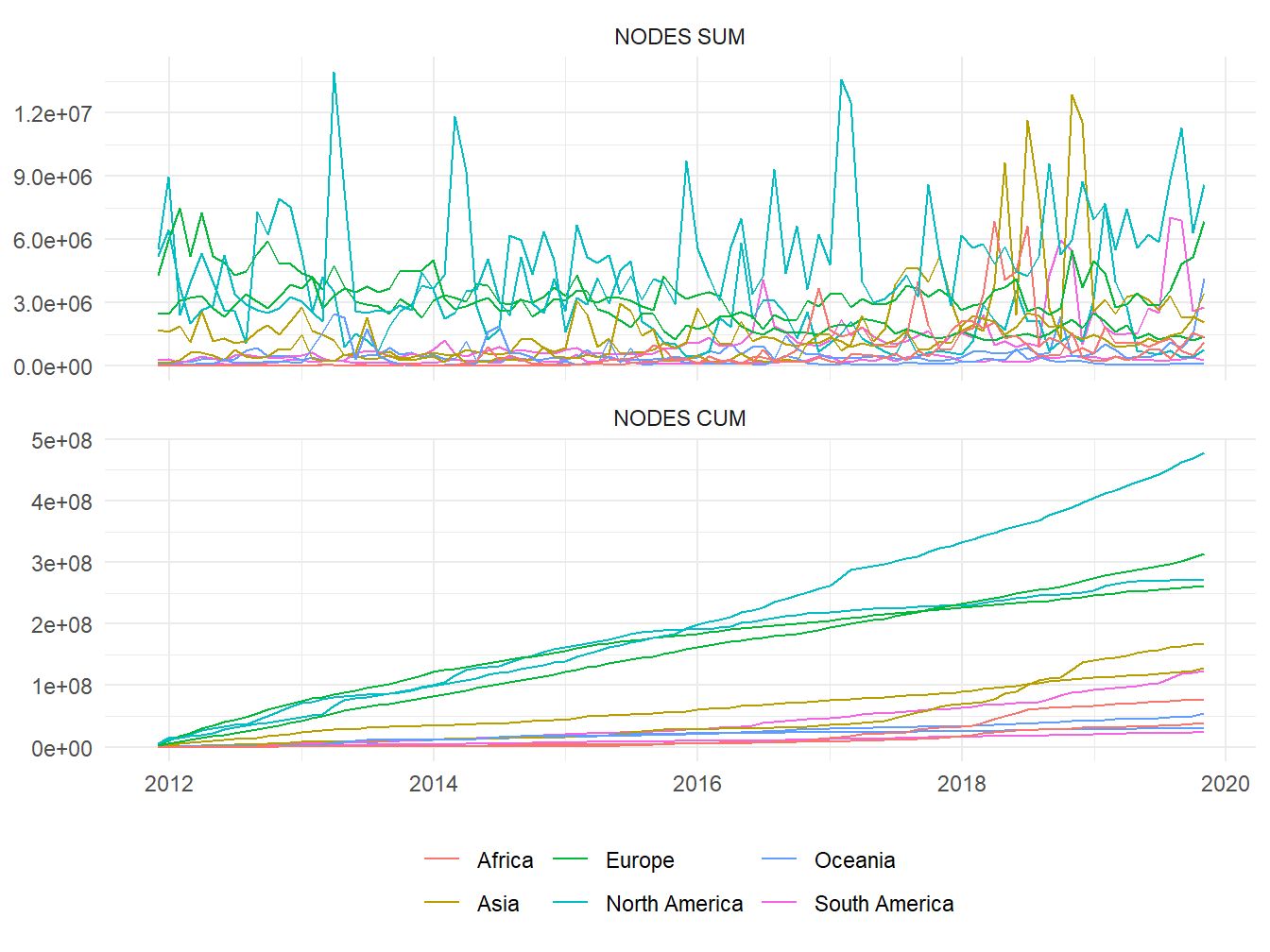
Figure 2: Suma 👆 y suma acumulativa 👇 de nodos creados mensualmente en países seleccionados
Como era de esperar, en los países europeos y norteamericanos se crean mayor cantidad de nodos; en pocos meses sucedió que fueron superados por un país de otro continente. Con todo, no resultará práctico modelar las contribuciones a través de la suma mensual de nodos; la suma acumulativa, en cambio, parece tener una evolución lineal. Estados Unidos presenta la mayor pendiente, seguido por el grupo de Rusia, Canadá, Francia, y finalmente los demás países. Argüiblemente en cualquier clase de proyecto, aspectos tales como cantidad de miembros o de contribuciones siempre tendrán un comportamiento lineal o exponencial; esto dependerá, en última instancia, del funcionamiento o del propósito del proyecto.
En OpenStreetMap ya se ha observado anteriormente un comportamiento lineal. Neis, Zielstra, and Zipf (2013), al comparar las contribuciones en doce grandes urbes alrededor del mundo, observaron un incremento lineal de los miembros que contribuyeron entre enero de 2007 y septiembre de 2012; esto se observó al normalizar el número de contribuyentes con respecto a la población o al área de la urbe. Las urbes, ordenadas de mayor a menor tasa de incremento de contribuidores, fueron:
- Berlín (🇩🇪)
- París (🇫🇷)
- Moscú (🇷🇺)
- Londres (🇬🇧)
- Los Ángeles (🇺🇸)
- Sídney (🇦🇺)
- Johannesburgo (🇿🇦)
- Buenos Aires (🇦🇷)
- Osaka (🇯🇵)
- Estambul (🇹🇷)
- Seúl (🇰🇷)
- El Cairo (🇪🇬)
Nuevamente, ciudades europeas son las que ocupan los primeros lugares, seguidas por una ciudad estadounidense. Un orden similar aparece en el siguiente gráfico (Neis, Zielstra, and Zipf 2013), que presenta el número de objetos -normalizados respecto al área- existentes en las mismas urbes.
Densidad de objetos OpenStreetMap en octubre de 2012; © 2014 Pascal Neis, Dennis Zielstra, Alexander Zipf
Con estos antecedentes se decidió ajustar una regresión lineal3 para cada país, modelando la suma
acumulativa de nodos creados con respecto al tiempo, en los ocho años (del 1 de noviembre
de 2011 al 31 de octubre de 2019) de las observaciones. Una manera organizada de llevar a
cabo esta tarea es utilizar tidyr::nest() para “anidar” las observaciones por país, y
luego ejecutar lm() en cada grupo anidado.
countries_model = nest(countries_month) %>%
mutate(model = map(data, ~lm(nodes_cum ~ date, data = .)),
model = map(model, ~c(coef(.), summary(.)$r.squared)),
name = list(c("intercept", "rate", "rsquared"))) %>%
unnest(cols = c(model, name)) %>%
pivot_wider(values_from = model)
head(countries_model)## # A tibble: 6 x 6
## # Groups: continent, country [6]
## continent country data intercept rate rsquared
## <fct> <chr> <list> <dbl> <dbl> <dbl>
## 1 Africa Algeria <tibble [96 x 3]> -65540524. 4211. 0.982
## 2 Africa Angola <tibble [96 x 3]> -38861484. 2443. 0.740
## 3 Africa Benin <tibble [96 x 3]> -28410417. 1791. 0.909
## 4 Africa Botswana <tibble [96 x 3]> -56111053. 3536. 0.898
## 5 Africa Burkina Faso <tibble [96 x 3]> -46220666. 2921. 0.927
## 6 Africa Burundi <tibble [96 x 3]> -13142257. 843. 0.857Para ilustrar los resultados, estas son las regresiones correspondientes a los doce países escogidos:
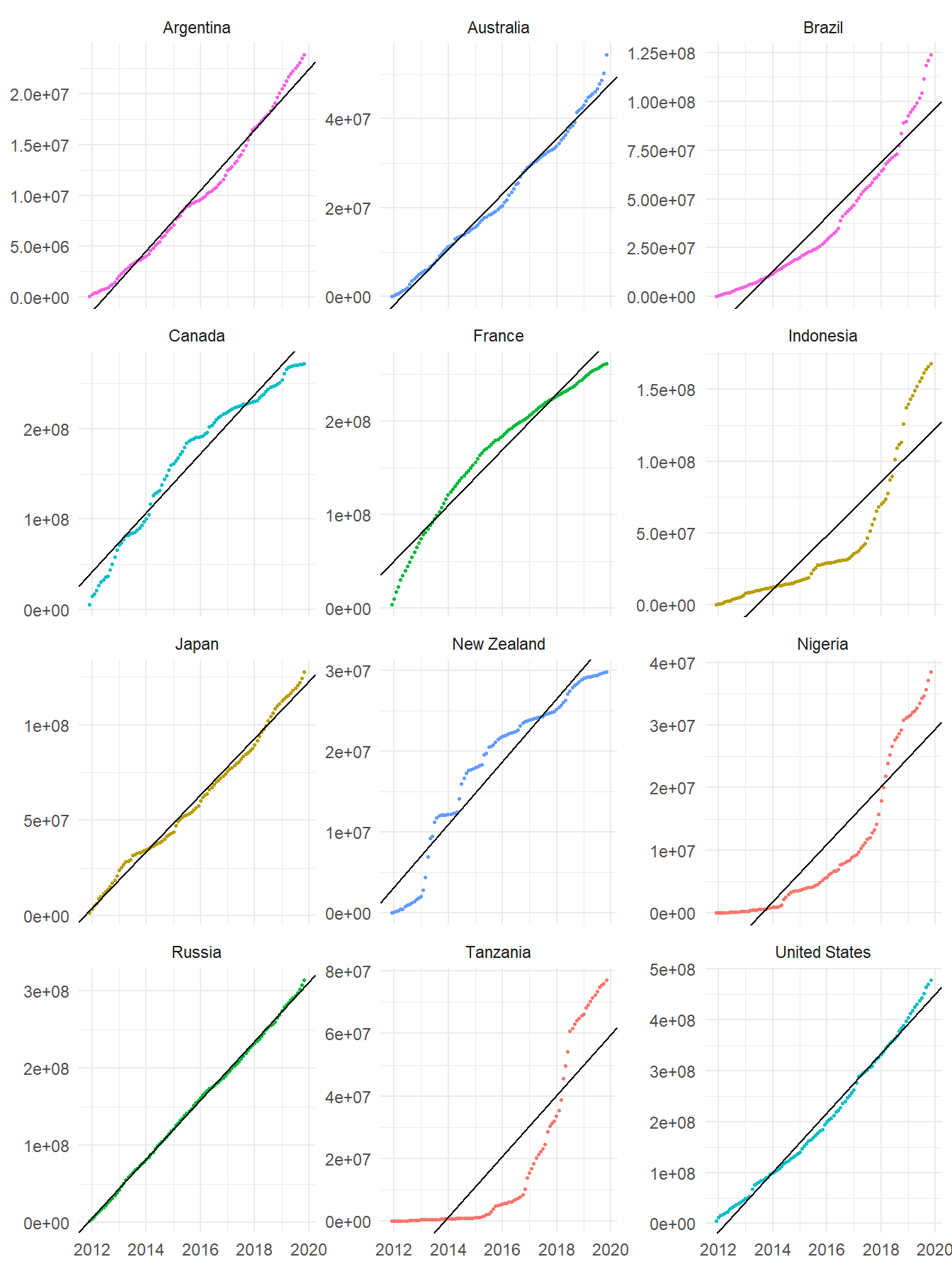
Figure 3: Regresiones lineales ajustadas en países seleccionados
En la mayoría de territorios se obtuvo un buen ajuste; la manera de evaluar esto es en función del coeficiente de determinación R2, que obtuvo un promedio de 0.8957. Solamente en nueve países (cuyas regresiones son presentadas a continuación) apareció un coeficiente R2 < 0.70; se trata de territorios que posiblemente fueron reconocidos recientemente en la fuente de los datos, o donde las contribuciones aparecieron de manera súbita.
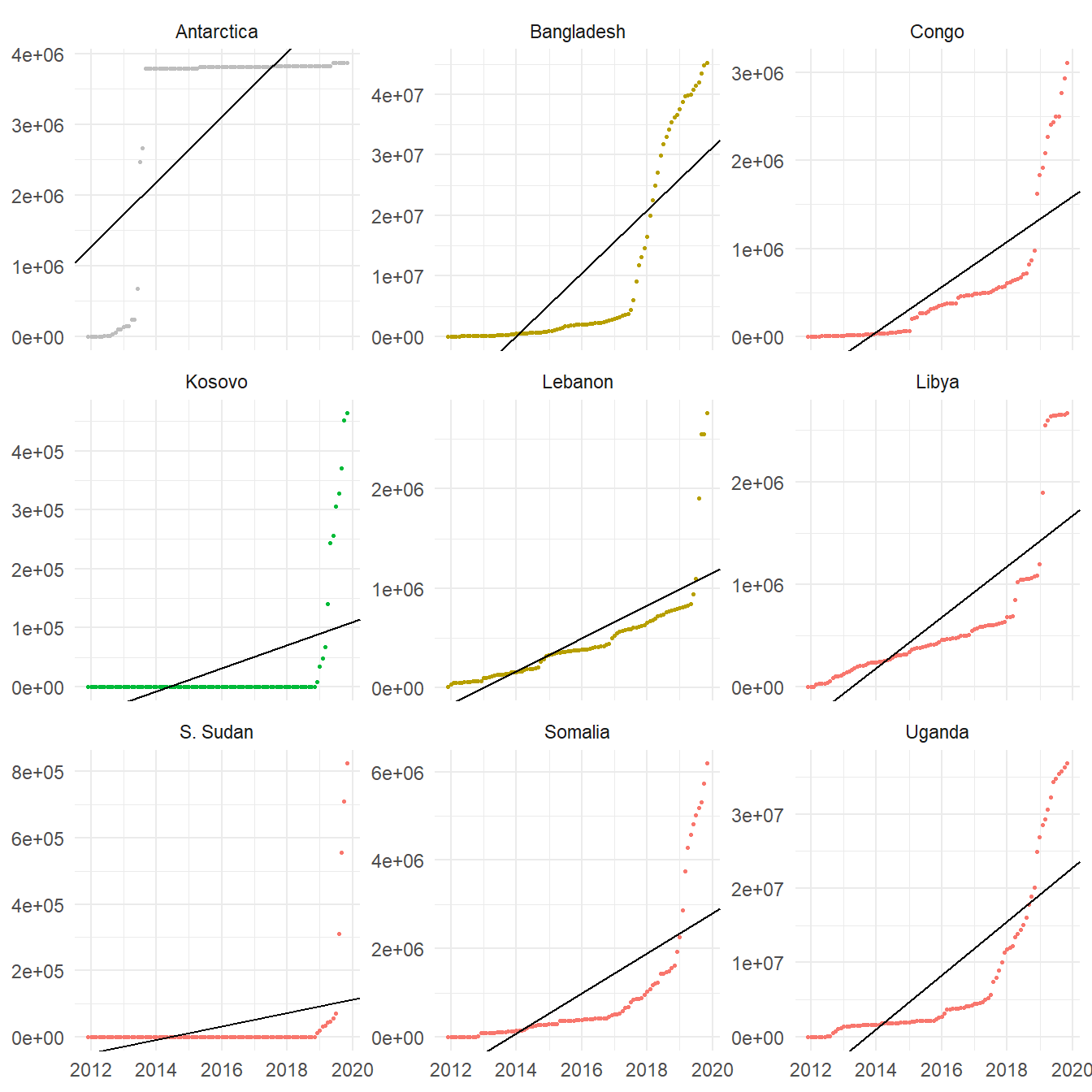
Figure 4: Regresiones lineales ajustadas con R2 menor a 0.70
Para los territorios que sí obtuvieron un buen ajuste, el parámetro estimado que define la evolución de las contribuciones en el tiempo es la pendiente de la regresión lineal; este valor representa la tasa ajustada de nodos creados diariamente4. La intercepción, en cambio, es irrelevante en este análisis particular. El promedio de la tasa de creación se situó en 9275 y el máximo en 159555 nodos diarios; este último es el caso de Estados Unidos, que constituye un valor atípico.
¿De qué manera podemos evaluar la exactitud de estas estimaciones? Neis and Zipf (2012) reportan que, en enero de 2012, la tasa total de contribuciones fue aproximadamente 1.2 millones de nodos, 130 mil vías y 1500 relaciones creados a diario en todo el mundo. Ahora, si sumamos las pendientes de todas las regresiones que ajustamos, obtenemos el valor mundial estimado de 1.605 millones de nodos diarios; es un valor mayor al reportado en 2012, lo cual tiene sentido pues ahora nos hallamos en una época con más contribuidores.
Para cerrar este artículo presentamos mapas coropléticos de las pendientes (que, como ya sabemos, son las tasas de crecimiento diario de los nodos) y de los coeficientes R2 de las regresiones ajustadas para cada país.

Figure 5: Tasa ajustada de nodos creados diariamente por país

Figure 6: Coeficiente R2 del ajuste lineal por país
Neis, Pascal, Dennis Zielstra, and Alexander Zipf. 2013. “Comparison of Volunteered Geographic Information Data Contributions and Community Development for Selected World Regions.” Future Internet 5 (June): 282–300. https://doi.org/10.3390/fi5020282.
Neis, Pascal, and Alexander Zipf. 2012. “Analyzing the Contributor Activity of a Volunteered Geographic Information Project — the Case of Openstreetmap.” ISPRS International Journal of Geo-Information 1 (December): 146–65. https://doi.org/10.3390/ijgi1020146.
Es importante notar que simplemente se sumaron los nodos creados cada mes, sin restar los eliminados. Como consecuencia, las tasas de crecimiento obtenidas al final de este artículo no sirven para calcular el número real de nodos en determinado país.↩︎
No olvidar que el número de países difiere ampliamente entre continentes, desde 7 en Oceanía, hasta 50 en África.↩︎
Considerando que el total de nodos comienza en cero, una regresión al origen (aquella donde la intercepción se fija en cero) es teóricamente un mejor modelo. Esa regresión también fue evaluada pero no generó mejor ajuste, comparada con la regresión lineal típica. Parece que este es uno de esos casos donde el modelo más sencillo es el indicado.↩︎
Es verdad que los datos fueron agregados mensualmente pero, debido a la manera como R maneja las fechas, la tasa indica el cambio esperado en los nodos, cuando la fecha aumenta en un día.↩︎